DynamoDB |
- DynamoDB NoSQL(Not Only SQL)


- 테이블 생성 시 스키마를 자동으로 생성한다.
NoSQL 이해하기 |
- 데이터 모델이 복잡해지고 방대한 양의 데이터를 보관할 때 드는 비용이 저렴하다는 사실을 알게 되었을 때 NoSQL은 IT 업계에서 각광받음.
- NoSQL에서 'No'는 'Not Only'로 사용되어 관계형 데이터베이스뿐만 아니라 NoSQL도 존재한다는 뜻입니다.
- NoSQL은 관계형 데이터베이스처럼 행과 열이 존재하는 테이블 형태가 아닙니다. 데이터 모델을 어떻게 설계하느냐에 따라 데이터베이스 포멧이 달라집니다.이는 크게 세 가지 로 나눌 수 있음.
NoSQL 포멧 3가지
1. 문서 데이터베이스
- 주로 JSON 형태의 문서를 보관합니다. 문서는 필드와 값으로 구성되어 있으며 문자열, 숫자, 배열 등 다양한 데이터 타입을 허용합니다.
2. Key-Value 데이터베이스
- 문서 데이터베이스와 비슷하나 구조가 훨씬 간단하며, 마찬가지로 Key - Value 형태의 JSON 데이터를 보관합니다.
3. 그래프 데이터베이스
- 노드와 엣지를 사용하여 데이터를 보관합니다.
DynamoDB 개념 잡기 |
- 테이블 안에는 아이템(item)이 들어있습니다. 아이템은 관계형 데이터베이스에서 행(row)와 개념이 비슷합니다. 따라서
{'customer_id':644, 'age':26, 'visit':True}가 하나의 아이템입니다.
- 특징은 열(column)과 개념이 비슷합니다. {'age' : [26, 31]}이 하나의 특징입니다.
DynamoDB 장점 알아보기 |
- DynamoDB 쿼리 속도는 타의 추종을 불허할 만큼 빠릅니다. 일반적으로 NoSQL 데이터베이스는 쿼리 속도(특히 읽기 속도)가 매우 빠릅니다. NoSQL은 테이블 비정규화 과정을 기본적으로 거치는데, 테이블 비정규화는 쓰기 퍼포먼스를 낮추는 대신 읽기 퍼포먼스를 극대화하는 것이 핵심입니다. 정규화 과정을 거친 테이블에는 중복 데이터(duplicated data)가 존재하지 않습니다. 정규화된 테이블에는 기본키(primary key)가 있으며 다른 테이블과 합쳐질 때 사용됩니다.
- 비정규화된 테이블은 이미 중복 데이터를 포함하고 있기 때문에 다른 테이블과 합치는 과정(join)이 필요 없습니다. 그러므로 쿼리 속도가 빨라지는 것입니다.
- DynamoDB는 오토스케일링 기능이 있습니다. 들어오는 데이터 크기에 따라 테이블 크기가 자동으로 변경됩니다. EC2인스턴스와 마찬가지로 DynamoDB 역시 데이터의 처리량에 따라 성능을 늘렸다 줄였다 합니다. 불필요한 자원을 줄여 비용을 대폭 절약할 수 있습니다.
- DynamoDB는 NoSQL이기 때문에 테이블 생성 시 스키마(schema)를 정의할 필요가 없습니다.
- 관계형 데이터베이스(RDS)는 가장 먼저 정의해야 하는 것이 스키마입니다. 스키마는 데이터베이스의 전반적인 구조 및 데이터 개체(entity), 속성(attribute), 등의 정보를 포함합니다.
- 스키마에는 하나 혹은 여러 개의 테이블이 존재할 수 있으며 다른 스키마와 어떤 관계에 놓여있는지에 대한 무결성 제약 조건(integrity constraint)을 정의할 수 있습니다.
- DynamoDB는 NoSQL이며 테이블 생성 시 기본키를 제외한 어떤 것도 미리 정의되지 않습니다. 개체와 속성을 미리 알 필요가 없습니다.JSON형태의 데이터가 들어오면 그대로 스키마와 테이블이 생성되며 데이터 타입이 자동으로 정의됩니다.
- DynamoDB는 SSD 스토리지를 사용합니다. 따라서 데이터를 읽고 쓰는 데 속도가 정말 빠릅니다.
기본키의 두 가지 종류 이해하기 - 파티션키 & 복합키 |
- DynamoDB는 다른 데이터베이스와 마찬가지로 기본키(Primary Key)(pk)가 있습니다. PK는 테이블에 있는 고유키이며, PK로 쿼리하여 원하는 데이터를 가져올 수 있고, 다른 테이블과 합칠 수도 있습니다. DynamoDB는 두 가지 기본키를 지원
1. 파티션키(partition key)
- 테이블에 있는 데이터를 파티션으로 나누고 분리시키는데 사용되는 키입니다. 실제로 데이터가 들어가는 장소를 정해줍니다. 여기서 장소란 DynamoDB안에서 해시 함수(hash function)을 실행시켜 반환되는 주솟값입니다. 따라서 하나의 장소에는 같은 데이터가 두 개 이상 있을 수 없습니다. DynamoDB는 데이터를 아이템 단위로 그룹화하여 보관합니다.
- 아이템은 여러 개의 스토리지에 분산되어 보관되는데 이를 파티션(DynamoDB 내부에 있는 물리적 스토리지)이라 부릅니다.

2. 복합키 (composite key)
- 여러 개의 키를 합쳐놨다는 뜻이며 살펴본 파티션키와 정렬키(sort key)를 합쳐놓은 것입니다. 정렬키는 파티션키로 데이터가 다른 장소로 분리된 다음 그 안에서 정렬키에 의해 데이터가 정렬될 때 사용되는 기준점입니다.
- 파티션키는 중복 데이터지만 정렬키는 중복되지 않습니다.
- DynamoDB 기본키는 파티션키 혹은 복합키 둘 중 하나를 반드시 선택해야 하며 정렬키만 기본키로 지정할 수 없습니다.

DynamoDB 데이터 접근 관리 |
- IAM을 통해 테이블 생성과 접근 권한을 부여할 수 있으며, 특정 테이블과 특정 데이터에만 접근을 가능하게 해주는 IAM 역활도 존재합니다.

좋은 DB 디자인을 하기 위해 알아야 하는 인덱스는 무엇인가? |
- 파티션키와 복합키를 올바르게 골랐다면 아무리 방대한 양의 데이터가 있어도 쿼리 속도는 빠릅니다.
- DynamoDB에는 인덱스(index)라는 개념이 있습니다.
인덱스란?
- 데이터 쿼리 시 테이블 전체를 스캔하는 것이 아니라 선택한 특정 열을 기준으로 쿼리가 진행됩니다.
- 인덱스에는 크게 로컬 보조 인덱스(local secondary index)(LSI)와 글로벌 보조 인덱스(global secondary index)(GSI) 두 가지가 있습니다.

1. 로컬 보조 인덱스
- LSI는 DynamoDB 테이블 생성 시에만 정의할 수 있습니다. 테이블을 만든 후 LSI는 변경 또는 삭제가 불가능합니다.
- 파티션키를 사용해야 하지만 정렬키는 다른 것을 사용할 수 있습니다. 즉, 똑같은 파티션키를 사용하더라도 정렬키가 다르기 때문에 전혀 다른 뷰를 생성할 수 있습니다. 파티션키와 복합키를 같이 사용하기 때문에 복합키를 사용한다고 말할 수 있습니다.

테이블과 뷰의 차이점
- 테이블은 데이터가 들어가기 위해 만들어지는 컨테이너이며 실제로 데이터가 존재하는 곳입니다.
- 뷰는 테이블과 마찬가지로 행과 열이 있으며 테이블과 구조가 똑같으나 뷰는 테이블에서 파생된 것이며 데이터가 들어있지 않습니다.
인덱스를 정의한다는 의미는 테이블에서 어떤 변화를 주는 것이 아니라 기존 테이블에서 새로운 뷰를 만드는 것입니다.
2. 글로벌 보조 인덱스
- GSI는 테이블 생성 후에도 추가, 변경, 삭제가 가능합니다. 뿐만 아니라 파티션키와 정렬키를 원래 테이블과 다르게 정의할 수 있습니다.
- 정렬키는 필수가 아니라 선택사항
- LSI와 달리 파티션키와 정렬키를 가지고 쿼리를 사용한다면 쿼리 성능을 대폭 끌어올릴 수 있습니다.

그럼 언제 LSI 혹은 GSI를 사용해야 하는가?
- 정렬키를 사용해 정렬된 데이터에서 하나의 파티션키가 들어있는 테이블을 주로 쿼리하는 상황이 발생할 경우 LSI를 권장합니다.
DynamoDB에서 데이터를 가져오는 두 가지 방법 |
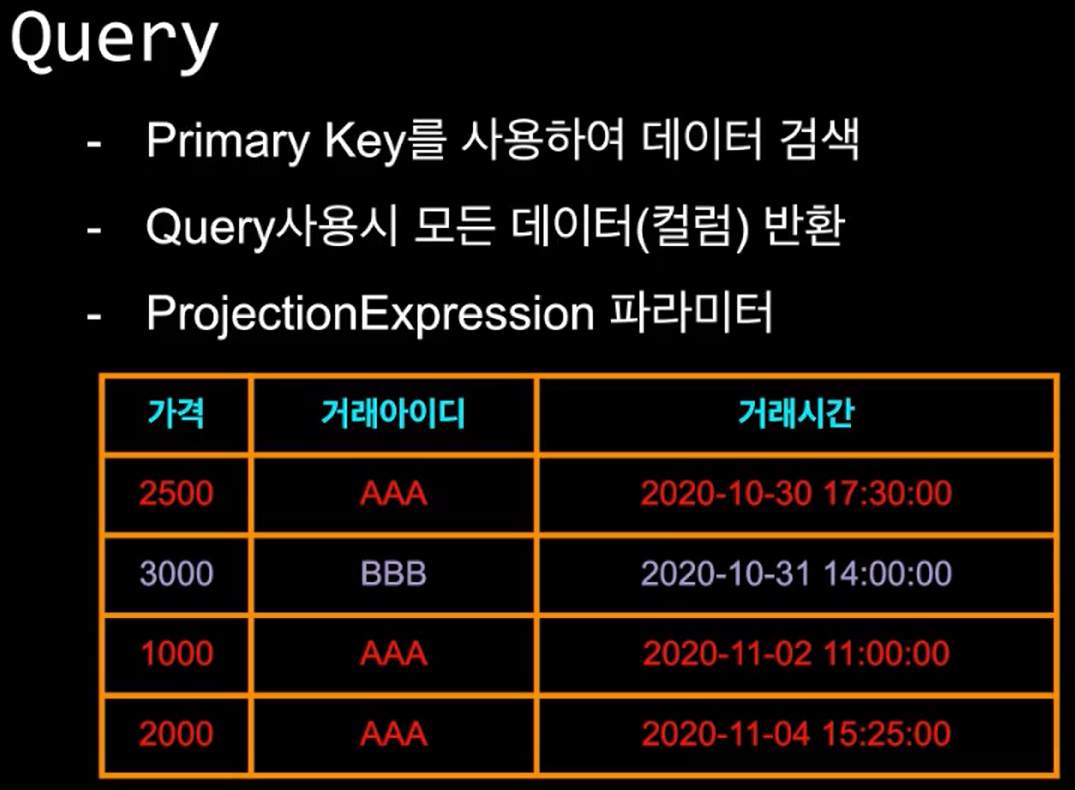
1. 쿼리(query)
- 테이블을 만들 때 정의한 기본키를 가지고 데이터를 가져오는 방법이다.
- 만약 쿼리를 하고 반환되는 데이터 양이 너무 많다면 정렬키를 제공하고 추가로 필터링하여 원하는 데이터를 가져올 수 있습니다.
2. 스캔
- 기본키를 사용하여 쿼리를 진행하는 것과 달리 스캔은 기본키를 사용하지 않고 테이블 안에 있는 모든 데이터를 불러옵니다.
-모든 데이터를 불러온 다음 필터를 따로 추가하여 원하는 데이터만 볼 수 있는 기능을 제공합니다.
- 스캔을 하면 테이블에서 한 번에 모든 데이터를 가져오는 것이 아니라 첫 1MB에 해당하는 배치(batch)데이터를 반환하는데 이것을 순차적 스캔(sequential scan)이라고 합니다.
- 수많은 스캔 일꾼을 여러 군데 분산키켜 병행하는 기능이 있으며 이를 통해 스캔의 성능을 비약적으로 향상시킬 수 있습니다.

DAX |

- 메모리를 캐시에 보관해서 데이터를 찾을 때 빠르게 찾는다. (읽을 때에만 해당)

- DAX는 클러스트를 만들고 클러스트의 환경설정을 설정해줘야한다.
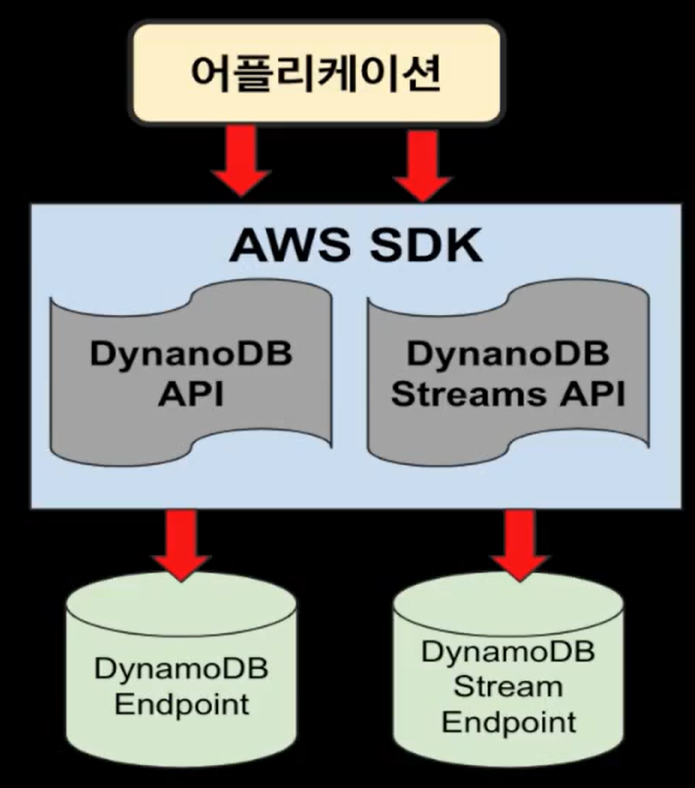
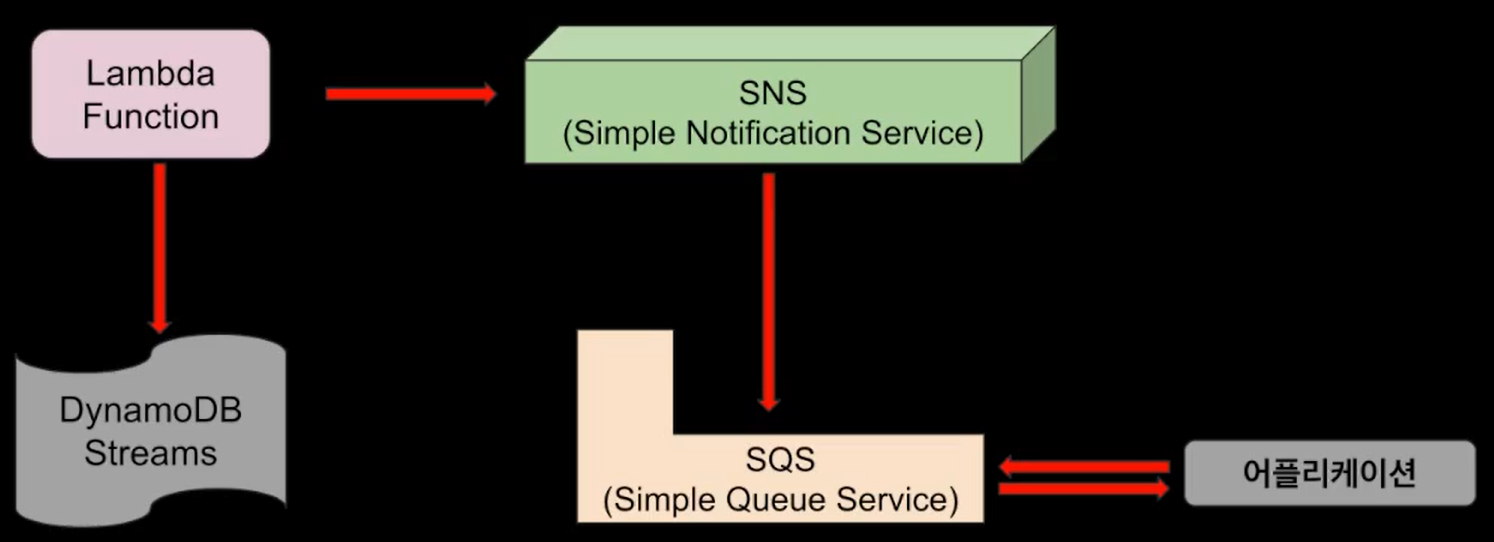
Streams |

API Gateway |
API(application programming interface)란?
- 두 개 혹은 그 이상의 컴퓨터 프로그램이 서로 소통할 수 있게 해주는 매개체 역활을 합니다.
Ex) 식당에 들어온 가족 <= API(주문..등) => 요리사
- 중간에서 요청을 받고 요청을 다른 곳으로 보내거나 처리하는 일을 합니다.
RESTful API
- REST(representational state transfer)은 상태 변화를 주기 위해 서버와 클라이언트 간 소통하는데 사용됩니다.
- 무언가를 새로 만들 때(CREATE), 어떤 정보를 불러올 때(READ), 이미 존재하는 데이터를 수정할 때(UPDATE), 마지막으로 존재하는 데이터를 삭제할 때(DELETE) 총 네 가지 요청을 사용한다.
- JSON 포멧으로 요청을 전달하며 요청받는 내용 역시 JSON 포맷입니다.
- 웹사이트 개발 시 서버와 클라이언트를 분리시킬 수 있다. 이를 모델-뷰-컨트롤러(model-view-controller)(MVC) 패턴이라 하며 클라이언트가 보는 뷰와 서버의 컨트롤러를 독립적으로 개발할 수 있는 유연성을 제공합니다.

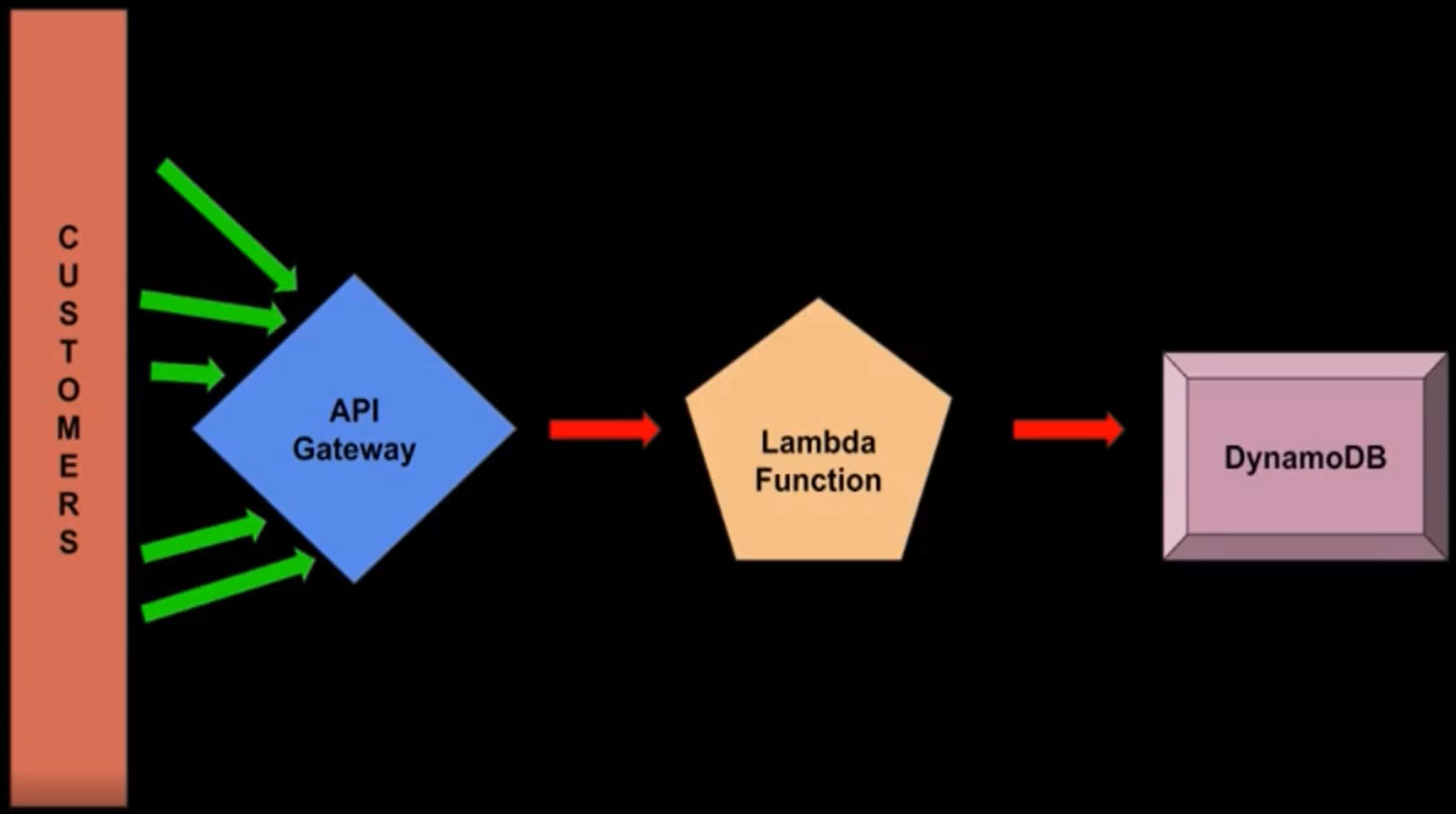
API Gateway
- 대부분의 애플리케이션은 앞서 배운 RESTful API 기반으로 운영된다.
- Authentication & Authorization
- 캐싱 시스템
- API Gateway는 뛰어난 확장성을 제공하며 직접 API를 만들고 이를 CroudWatch에서 모니터링하는 기능이 있습니다.
- EC2 인스턴스에서 돌아가는 서버 및 웹 애플리케이션에 접근하여 API 기능을 추가할 수 있습니다.
- 페이고 원칙을 따르기 때문에, API 요청 처리 시간에 따라 비용을 지불한다.
- API Gateway는 AWS로부터 추가적인 보안층(security layer)을 전달받아 DOS공격, SQL 주입 공격(SQL injection)같은 것으로부터 보호를 받습니다.
- API Gateway의 목적지는 크게 네 가지로 생각할 수 있습니다.
1. 전 세계 모든 사람에게 공개된 API
2. 특정 사람에게만 접근 가능한 비공개 API
3. 그밖에 다른 사용 사례를 지닌 API 또는 다른 AWS 리소스로 요청 결과를 전달하는 서비스형 함수(function as a service)


CI/CD 파이프라인 |
지속적 통합(continuous integration)(CI)
- 코드를 중앙 리포지토리에 올려 다른 개발자가 개발하는 코드에 지장 없이 테스트하여 코드가 원하는 결과물을 만들어내는지, 잘 돌아가는지 검증합니다. 만약 에러가 발생한다면 CI를 통해 손쉽게 해결하여 불필요하게 발생하는 에러를 줄일 수 있습니다. 개발자는 CI를 통해 코드 충돌을 피하고, 본인 코드에만 집중할 수 있습니다.
지속적 배포(continuous deployment)(CD)
- 하루에 수십 개의 버그를 고치고 프로덕션에 배포하여 서버의 다운 및 소프트웨어 셧다운 현상을 피해 사용자가 불편함을 느끼지 못하도록 해야 합니다.
CI와 CD는 공존합니다.
CI/CD의 장점 |
1. CI/CD는 소프트웨어 개발 시 반복적 작업을 모두 자동화합니다.
2. 점진적 변화(incremental change)를 추구할 수 있습니다.
리포지토리 개념 |
- 리포지토리는 코드를 보관하며, 회사나 단체에서 수많은 개발자가 코드를 공유하고 수정하는 곳입니다.
브렌치 |
로컬 브렌치(local branch)
- 개발자가 프로그램을 개발하고 테스트하는 곳이며, 마스터 브렌치는 실제 프로덕션에서 사용되는 코드를 담고 있는 곳입니다.
마스터 브렌치(master branch)
- 실제 프로덕션에서 사용되는 코드를 담고 있는 곳입니다.
로컬 브렌치에서 모든 테스트가 성공하면 마스터 브렌치로 코드가 합쳐집니다.
리포지토리 |
로컬 리포지토리
- 개발자가 로컬 브렌치를 만들고 코드를 구현한다.
원격 리포지토리
- Ex) 개발자가 브렌치를 만들고 코드를 구현합니다. 깃허브에서 생성한 리퍼지토리..
코드 커밋 |
CI/CD 파이프라인 구축하기 위해 필요한 첫 번째 리소스인 코드 커밋(CodeCommit)
- 파일(코드, 이미지, 동영상, 문서, 애플리케이션을 돌리기 위해 필요한 다양한 라이브러리 등)을 보관하는 저장 장소로 사용된다.
코드 배포 |
- CI/CD 파이프라인에서 가장 큰 비중 차지
- 코드 커밋을 통해 마스터 브렌치로 병합된 후 실제 프로덕션으로 배포하기 위해 코드 배포를 거쳐야 하기 때문입니다.
- 코드 배포는 한 마디로 정의하면 '자동 배포(automated deployment)'
자동 배포의 이점
1. 새로운 기능을 빨리 프로덕션으로 배포할 수 있습니다.
2. 프로덕션 배포를 하는데 개발자의 개입이 전혀 필요 없습니다.
코드 배포의 종류( 롤링 배포, 블루그린 배포 ) |
1. 롤링 배포(rolling deployment)
- 점층적 배포
2. 블루그린 배포(blue/green delployment)
- 블루는 현재 돌아가고 있는 프로덕션을 뜻하고, 그린은 새로 배포할 인스턴스를 의미한다.
- 블루그린 배포의 궁극적 목표는 블루를 완전히 셧다운시키고 그린을 100% 활성화하는 것입니다.
- 이전 버전과 최신 버전으로의 전환이 매우 용이하다.
* 맨 처음 배포할 때 롤링 배포를 사용한다.
* 시간이 지나면서 인스턴스의 개수가 늘어나고 인프라가 복잡해지면 그때 블루그린 배포 사용을 권장합니다.
'[AWS]' 카테고리의 다른 글
| AWS Certified Solutions Architect #3 (0) | 2023.11.06 |
|---|---|
| AWS Certified Solutions Architect #1 (0) | 2023.11.01 |
| AWS(Amazon Web Service) 입문자를 위한 강의 #3 (0) | 2023.10.18 |
| AWS(Amazon Web Service) 입문자를 위한 강의 #3 (0) | 2023.10.16 |
| AWS(Amazon Web Service) 입문자를 위한 강의 #2 (0) | 2023.10.12 |


